Continuous Delivery of Safe AI#
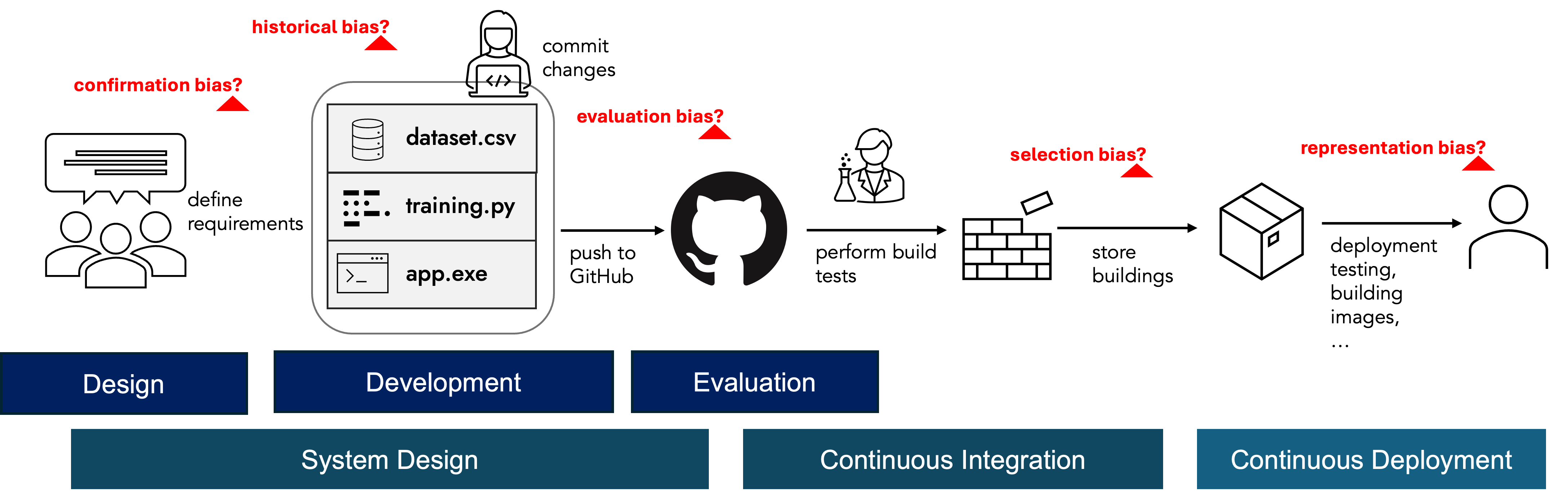
The above diagram illustrates a simplified ML development pipeline. A typical pipeline consists of multiple branches with iterative processes, involving multiple contributors. Different forms of bias types can occur in each step. In this complex environment, metadata management appears as an important part of assurance process.
Defining safety-aware CI/CD type flows that can automate building multiple artefacts for different teams can support building a common understanding in bias mitigation for organisations. In this article, we demonstrate potential approaches to monitor ML pipelines throughout the development lifecycle.
Prerequisites#
Structuring an ML project requires similar skills to any data-centric research. We recommend reviewing the following tips to support your design and management process. The key requirement to monitor the potential fairness (or security, privacy, etc.) issues is maintaining a clean and maintainable code. There are many great books about maintaining a healthy codebase, so I will not go into details here.
You can check NCSC’s guidance on secure development and deployment of software systems.
The Turing Way project provides a set of useful reading materials to organise your codebase for reproducibility: https://book.the-turing-way.org/reproducible-research/reproducible-research
These resources are free. If you would like to read some books, see the list below.
See also
Recommended books:
Structure and Interpretation of Computer Programs (SICP) by Ableton, Sussman, Sussman
The Pragmatic Programmer by David Thomas, Andrew Hunt
Architecture Patterns with Python: Enabling Test-Driven Development, Domain-Driven Design, and Event-Driven Microservices by Bob Gregory and Harry Percival
CI/CD: Continuous Integration and Delivery#
Before starting automating the parts of your codebase (e.g. testing your code against adversarial scenarios, building releases), I suggest checking the prerequisities of this article and structure your clean and reproducible codebase.
CI/CD stands for Continuous Integration and Continuous Delivery (or Continuous Deployment). It is a software development practice where code changes are automatically tested and integrated (CI), and then automatically delivered or deployed to production (CD), ensuring faster and more reliable updates. Based on your needs, integration and delivery parts can be automated via different libraries, and you can maintain the overall pipeline through tools provided by Github.
Check these examples:
A Good Example of a Complete RAG Application: octodemo/contoso-chat-dhanachavan
Example Actions: microsoft/security-devops-action
Using Tools for Experiment Tracking#
You can use tools like wandb, Neptune, and mlflow to track and maintain records of your ML experiments. These open-source platforms allow you to register models and experiments for easy maintainability.
While these libraries are useful for tracking progress and sharing insights with your team, they aren’t optimised for AI Safety assurance-focused processes (Inspect AI from UK AISI can be an exception, but its coverage of safety in terms overlook characteristics of responsible AI such as fairness is limited). In such cases, it’s important to foster interdisciplinary conversations and track fairness metrics, discrimination cases, and related outputs.
An example flow of experiment tracking as part of metadata management is illustrated below:
import libraries[wandb, mlflow, ...]
init project, config, libraries
set experiment_context
run experiment
log metrics for each epoch
In this flow, we have four key entities: Context, Model, Data, and Metrics. Effectively tracking these entities can allow us to effectively achieve transparency characteristic of trusted AI. And ease the final development of transparency artefacts such as use case cards, model cards, and data cards.
Why do we need an additional effort for good logging practices#
Although, in software engineering domain, we achieved good test engineering practices (I might need to reassess statement after all the fuss around vibe coding), ML community doesn’t follow the same practices in most development scenarios. When experimenting with data and models, we generate a large amount of information, coming from different departments. For example, in a data science department, one responsibility can be assessing fairness, while another developer might focus on improving robustness across timeframes. These two data scientists can come up with different considerations for the model, hence requires an extensive review before the update of the model.
A good logging practice that focuses on trusted AI characteristics can streamline this process. By proactively defining the minimum requirements and automatically monitoring the parameters related to these requirements, we can:
Reduce Workload: Automate the extraction and logging of relevant fairness metrics, freeing ML engineers from the manual task of selecting and providing this information.
Minimize Errors: Decrease the likelihood of mistakes that can occur with manual data handling and reporting.
Ensure Consistency: Maintain a standardized approach to logging fairness-related data, which can enhance the reliability and comparability of fairness assessments.
Enhance Focus: Allow fairness researchers to concentrate on analyzing the relevant data without the distraction of unrelated information.
What about version control in ML (e.g. CMF and DVC)?#
The design principles of our metadata management shares the similar design decisions with CMF and DVC to allow quick and easy integration with these data and model driven version control systems. While developing our tool, we also checked the compatability of using the tool together with CMF and DVC to allow version control throughout the fairness research lifecycle.
Note
#TODO: Add VCS workflows
A checklist for opening data and models#
Creating an open-source ML repository demands additional requirements to responsibly release the outputs. Model Openness Framework defines three layers while assessing openness and completeness of AI development artifacts.
Open Model layer includes model architecture, model parameters, technical report, evaluation results, model card, data card and sample model outputs.
Open Tooling layer includes the codes of training, inference, evaluation, data used for evaluation, supporting libraries and tools, and all components from Open Model layer.
Open Science layer includes research paper, all datasets, data pre-processing code, model parameters, model metadata, and all components of Open Tooling layer.
Delivering all these artifacts continuously in a transparent way requires a good carefully designed comprehensive orchestration flow.