Fairness Reporting#
Auditing the fairness of AI models is a challenging process as defining what fairness means depends on the context of a specific application. Auditing an algorithm, regardless of its type, is a dynamic and non-linear process. Koshiyama et al. demonstrated the interrelation between development stages and auditing verticals in five main steps [Koshiyama et al., 2021]:
Stages: |
Data and Task Setup |
Feature pre-processing |
Model selection |
Post-processing and Reporting |
Productionizing and Deploying |
|---|---|---|---|---|---|
Explainability |
Data collection and labelling |
Dictionary of variables |
Model complexity |
Auxiliary tools |
Interface and documentation |
Fairness |
Population balance |
Fair representations |
Fairness constraints |
Bias metrics assessments |
Real-time monitoring of bias metrics |
In this process, keeping a recording of experiment findings and reporting them is a challenge for many development teams. FAID reports can support developers visualise and share the fairness-related data with other stakeholders in the development process.
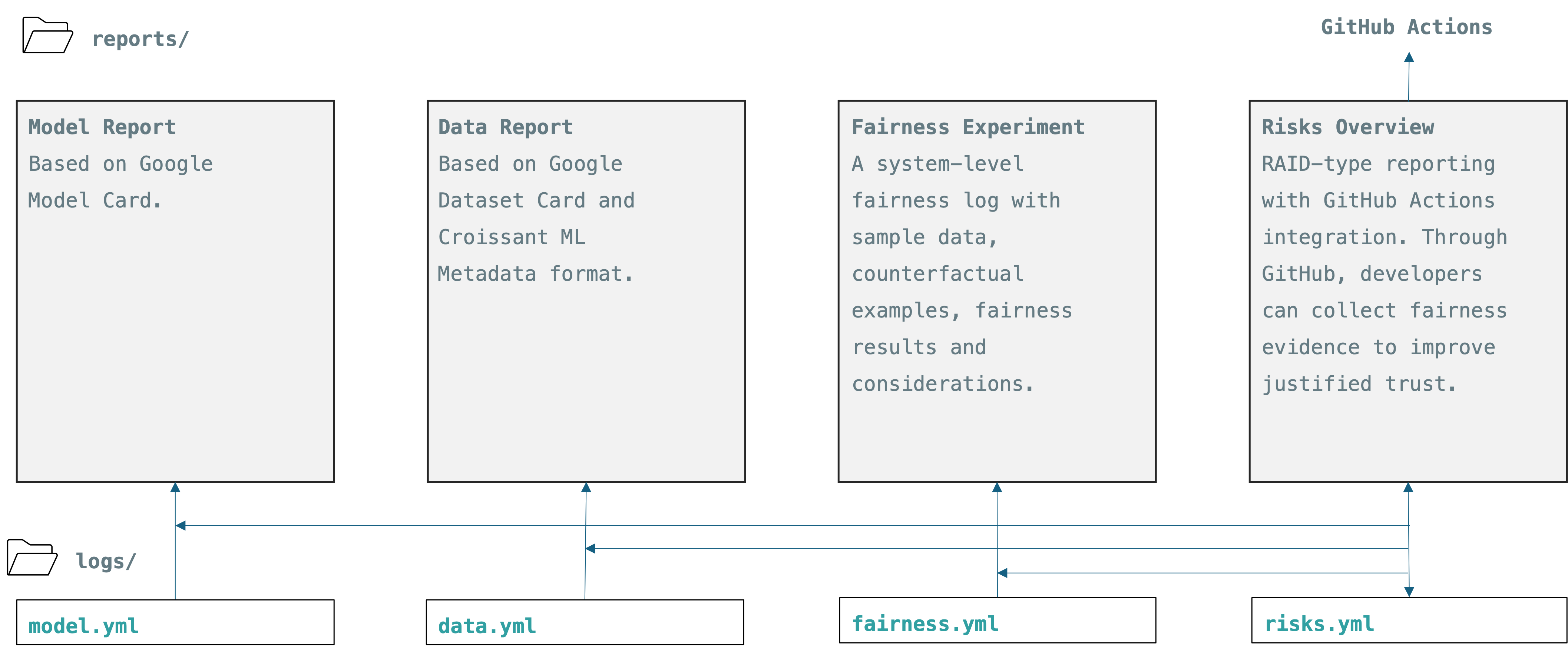
Standardised Recording of Metrics#
FAID utilises Franklin et al.’s Fairness Metrics Ontology [Franklin et al., 2022] as the standard relational map of fairness notions and metrics. So, any fairness experiment report follows the organisational hierarchy of this ontology:
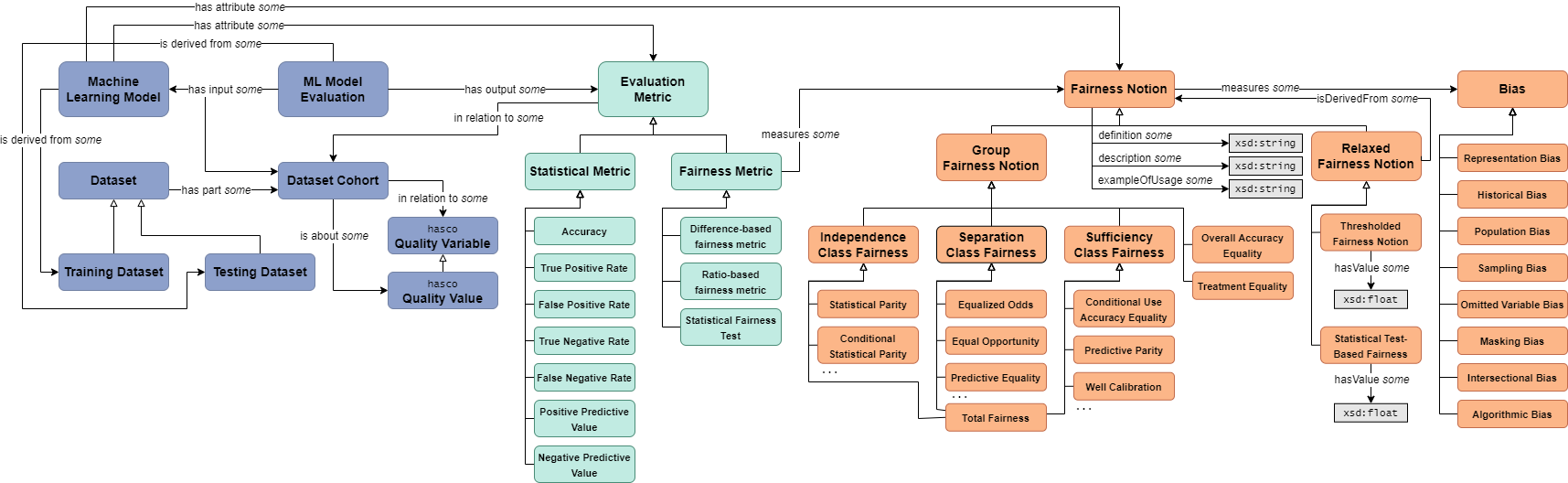
See the ontology schema here: frankj-rpi/fairness-metrics-ontology
And for each fairness metric, each bias evaluation and mitigation result follows this schema in the reporting:
bias_metrics:
groups:
group_name:
description: ""
label: ""
metrics:
- name: ""
description: ""
value: 0
threshold: 0
bigger_is_better: ""
label: ""
notes: ""
sg_params: {}
This way, FAID can record the results in a fairness library agnostic way. Using this ontology can support developers by,
Clarifying purposes and distinctions of notions and metrics, and
Demonstrating whether a given fairness notion can be derived from a certain underlying metric, or which combinations of metrics are equivalent to other metrics.
Providing a structured, clear dependency between notions (if a model satisfies one notion, it will also satisfy all superclasses of that notion).
Developers can further create knowledge graphs for risk management strategies, and later create automated inferences to aid in selecting and interpreting fairness metrics and fairness-based ML evaluations.
ML Pipeline Fairness Monitoring Principles#
The data metada goes to data.yml. The fairness experiment data is in the corresponding experiment log (e.g. fairness_exp0.yml) Before the release of data (or before sharing with other teams) the data log file should be updated based on fairness experiment results.
The log entities are structured to help teams record and monitor the following steps in a machine learning pipeline:
1. Dataset Bias Identification and Evaluation#
Data Source Examination: [fairness.yml:data:sensitive_characteristics]. Evaluate the origin of your data. Ensure diverse representation across different demographics or categories relevant to your use case.
Class Imbalance Check: [fairness.yml:data:variable_profile]. Use statistical methods to check for class imbalances (e.g., compare counts across different groups). Ensure that minority groups are adequately represented.
Correlation with Sensitive Attributes: [fairness.yml:data:variable_profile] Test for correlations between features and sensitive attributes (e.g., gender, race). Identify if any input features are disproportionately correlated, which could lead to biased outcomes.
Distribution Analysis: [fairness.yml:data:variable_profile] Assess distributions of sensitive attributes in both training and test datasets. Ensure that the test set is not biased compared to the training set.
2. Preprocessing Techniques for Bias Mitigation#
Data Augmentation: [fairness.yml:data:augmentation] If some groups are underrepresented, use augmentation techniques to artificially increase the representation of those groups.
Re-Sampling: [fairness.yml:data:preprocessing] Over-sampling for minority classes or under-sampling for majority classes can address imbalance, however such re-weighting algorithms might also result in reducing the overall accuracy.
Fair Representation Sampling: [fairness.yml:data:preprocessing] Implement techniques like stratified sampling to ensure a balanced representation of subgroups.
Sensitive Attribute Removal: [fairness.yml:data:preprocessing] Remove sensitive attributes if not required for the model, but be cautious of proxy variables that might still carry sensitive information.
3. Bias in Feature Engineering#
Feature Relevance Analysis: [fairness.yml:data:model] and [fairness.yml:bias_metrics] Analyze the importance of features in your model. Eliminate features whose impact on the outcome introduces unnecessary or discriminatory bias.
Non-Sensitive Feature Derivation: [fairness.yml:bias_metrics] Ensure that any new derived features do not inadvertently reintroduce bias by correlating too closely with sensitive attributes.
4. Algorithmic Fairness Checks#
Algorithm Selection: [fairness.yml:model] Choose algorithms that are less prone to overfitting, as overfitting can exacerbate biases in the data.
Model Explainability: [fairness.yml:postprocessing] Use explainable models (or post-hoc explainability tools for black-box models) to identify how different features affect predictions for different groups.
Hyperparameter Tuning: [fairness.yml:postprocessing] Regularize models to reduce the potential for bias amplification during training.
5. Bias Evaluation Metrics#
Group Fairness Metrics: [fairness.yml:bias_metrics] Ensure that the prediction or error rates are similar across groups.
Individual Fairness: [fairness.yml:bias_metrics] Verify that similar individuals receive similar predictions, regardless of sensitive attributes.
Calibration across Groups: [fairness.yml:bias_metrics] Ensure that predicted probabilities are well-calibrated across different demographic groups.
6. Post-processing Bias Mitigation#
Outcome Adjustment: [fairness.yml:postprocessing] After training, adjust decision thresholds for different groups to balance outcomes. For example, tune thresholds to equalize false positive or false negative rates.
Reject Option Classification: [fairness.yml:postprocessing] During model deployment, allow borderline cases to be classified with manual review to reduce the likelihood of biased outcomes.
Fairness-Constrained Optimization: [fairness.yml:postprocessing] Incorporate fairness constraints directly in the optimization process of your model to ensure that fairness objectives are met.
After the experiment, practitioners should also monitor:
7. Deployment:#
[risk.yml] can be used to share risks and issues with other team members.
Monitor for Drift: Regularly monitor model inputs and outputs for data drift that might introduce bias over time.
Feedback Loop: Collect feedback from stakeholders (users or domain experts) to identify any perceived biases that were not anticipated during training.
Continuous Re-Evaluation: Re-evaluate the model periodically to assess if biases have emerged due to changing input data or real-world conditions.
8. Human-in-the-Loop Strategies#
[data.yml:rai] and [model.yml:rai] entities are structured keep a record about these information.
Manual Review of Outputs: Implement a human-in-the-loop mechanism for reviewing predictions that have a higher likelihood of being influenced by bias.
Bias Review Committee: Establish a diverse team to periodically audit the model and its outputs for potential bias.
9. Ethical and Contextual Considerations#
[data.yml:rai] entity is structured keep a record about these information.
Stakeholder Involvement: Engage affected communities or stakeholders during the model design and evaluation stages to understand which biases are most critical to mitigate.
Impact Analysis: Consider the social impact of false positives and false negatives for each group. Bias mitigation should prioritize minimizing harm to vulnerable groups.
Transparency and Documentation: Document all steps taken for bias mitigation and evaluation. Clearly communicate limitations and biases that may remain.
Linking these Principles to Equality Act#
The Equality Act (such as the UK’s Equality Act 2010) aims to protect individuals from discrimination and promote equality across various protected characteristics, including age, disability, gender reassignment, race, religion or belief, sex, sexual orientation, marriage and civil partnership, and pregnancy and maternity. Here, we summarised how bias evaluation and mitigation principles can align with Equality Act considerations to ensure compliance and ethical alignment. Each item starts with the corresponding entity of our standardised recording format:
[fairness:data:sensitive_characteristics] In the data quality assessment, we can ensure that datasets are inclusive of all protected characteristics to avoid direct or indirect discrimination. Data collection should represent protected groups to avoid underrepresentation, which could lead to unfavorable treatment of certain demographics. Further, identifying and mitigating any imbalances to prevent discrimination against underrepresented groups can support achieving fairness by balancing groups.
[fairness:data:preprocessing] Augmenting data for underrepresented groups is tricky. It can help fulfilling the Act’s requirement to ensure all groups have equal representation and opportunities. However, it can also create inorganic scenarios and create some kind of indirect discrimation.
[fairness:data:preprocessing] Removing sensitive attributes is a standard approach in “fairness through unawareness”. It can prevent direct discrimination. To comply with the Act, data should be processed in such a way that no undue bias related to protected characteristics is introduced.
[fairness:data:variable_profile] Practitioners should further explore whethr new features reintroduce protected characteristic information in unintended ways. Derived features must be assessed to avoid indirect discrimination.
[fairness:model] Algorithm choice should align with the Act’s requirements to ensure fair and equal treatment.
[fairness.yml:postprocessing] Understanding how models make decisions helps ensure fairness across protected groups. Transparent model behavior supports accountability and compliance with anti-discrimination standards.
[fairness.yml:bias_metrics] Fairness metrics directly address the requirements for non-discrimination and equal treatment. Models should be evaluated using these metrics to ensure no group or individuals within protected groups experiences unfair treatment or disadvantage.
[fairness.yml:postprocessing] Adjusting thresholds in model decision making can help balance outcomes, reducing the risk of adverse effects on vulnerable groups. These kind of post-processing adjustments align with promoting equal outcomes as per the Equality Act’s provisions. However, it should also be carefully monitored.
Further considerations throughout the ML pipeline includes:
Gathering continuous feedback from the deployment pipeline can reveal biases that negatively affect protected groups. A feedback loop helps maintain compliance by addressing new sources of discrimination as they arise.
A human review helps ensure that sensitive cases are not unjustly treated. Manual oversight is essential for ensuring fairness, especially when automated decisions might disproportionately impact certain groups.
Including affected communities helps understand biases from their perspective. Engagement with protected groups ensures that models are developed and evaluated in line with the principles of equality and non-discrimination.
Understanding the social impact ensures that decisions do not unjustly harm any protected group. Mitigating harm for vulnerable groups directly aligns with the Equality Act’s objective to protect against adverse impacts.
Transparent reporting aligns with legal requirements, providing a basis to demonstrate adherence to equality and anti-discrimination standards. Check Algorithmic Transparency Recording Standard Hub.